
9/13/2024
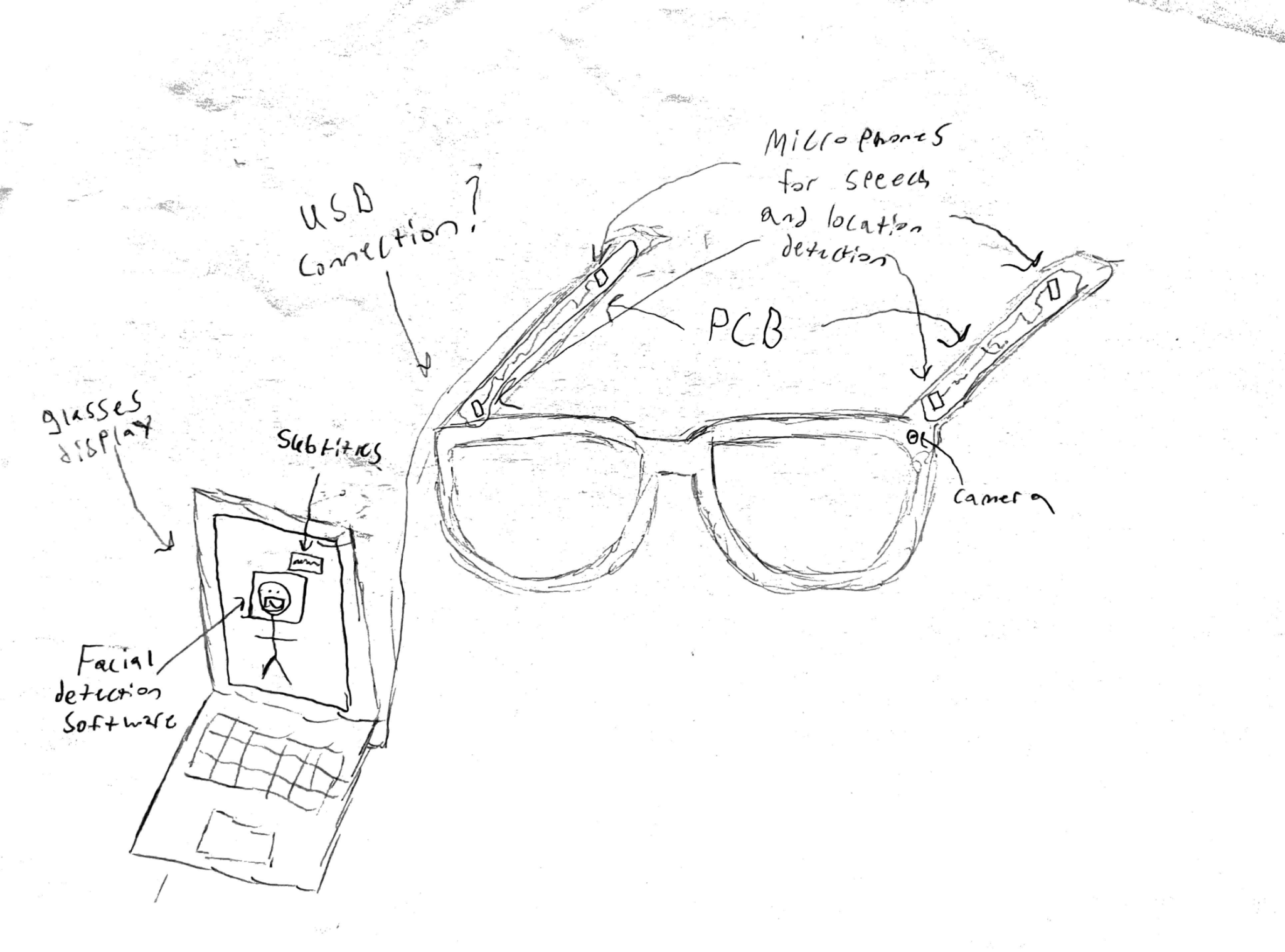
The image above is my sketch of what I think the “IRL Subtitles” project will look like by the end of the semester. My goal this week to start working towards this final product will be to begin formulating a working “Facial Detection” program for our glasses.
This will be broken up into a few different steps:
- determining the language: the language that everything will be done in will most likely be python.
- Obtaining an open source facial detection software to begin working on: this will most likely be from “Open CV” but if a better alternative is found I will switch to that.
- Finally, I will try to have a complete or near complete facial detection software that is able to recognize facial expressions and when someone is talking.
If I complete this soon enough I may also assist In the testing phase of comparing sound signals for localization.
9/22/24 Progress Report 1:
This week was productive in terms of progress for the Facial Detection software.
- The determined language was python and everything software related for the “IRL Subtitles” will be written in python. However, I had a lot of difficulty getting the software to run in a WSL2 environment because the WSL2 environment I was using did not support accessing webcams or other hardware devices directly. So for now I am just running everything on my windows system but this may switch to a “Docker” environment.
- I decided on using the open source facial detection software from “open CV” combined with the lip detection software from the previous semesters work in order to create an effective facial and lip detection software shown in the photo below. I got to the point of having it functioning as a face a lip detector.
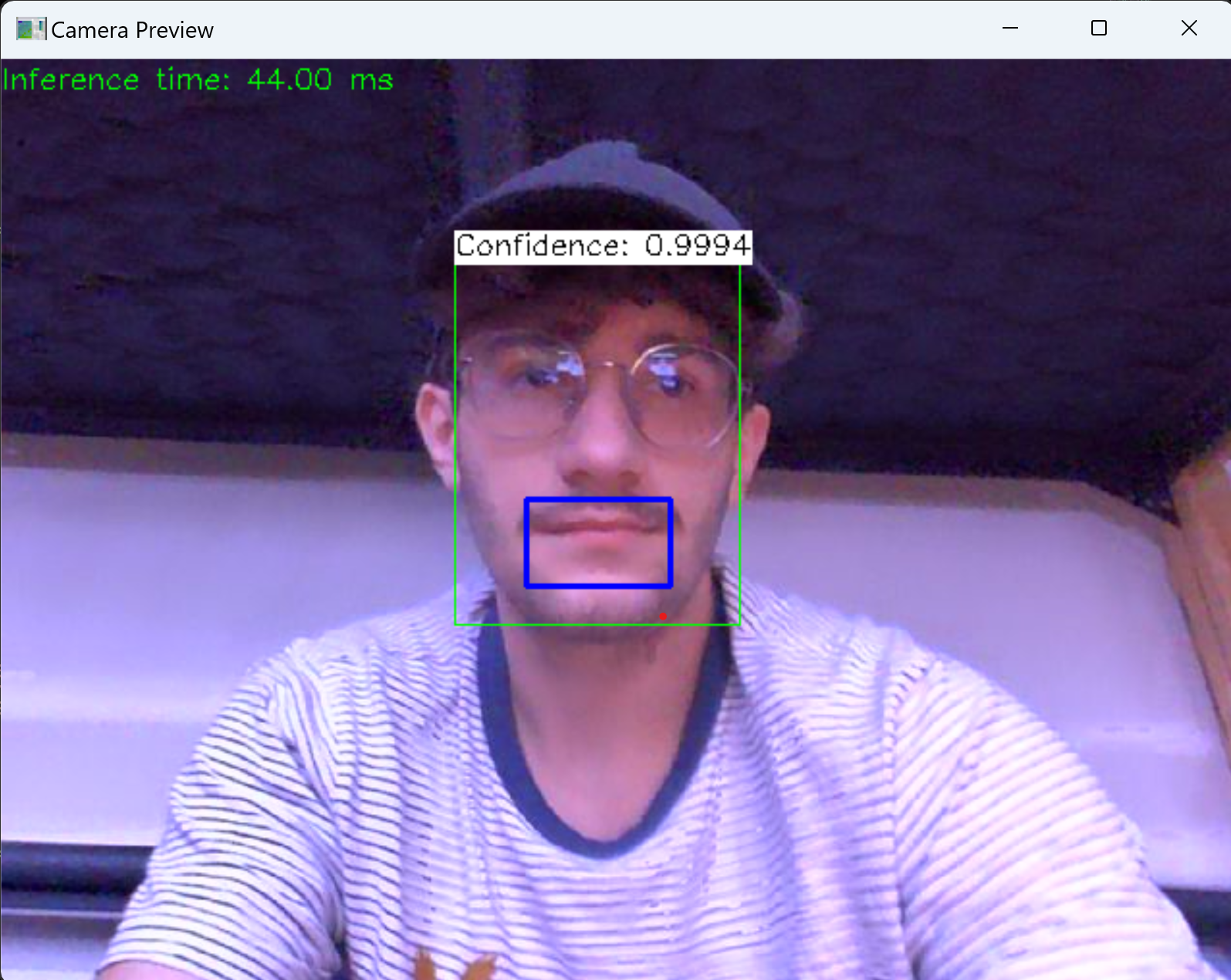
For next week I will still need to complete a speech detection feature that determines when someone may be talking. This was already completed in the previous semester I just need to implement it to work in the new python file.
To Do List Week of 9/23/24:
My goal for this next coming week is to complete the facial detection software and make improvements where needed. Also, I will begin assisting with another task such as sound localization or the hardware testing side of things. This can be broken up like this:
- Finish the facial detection by having the ability to determine when someone might be speaking.
- Consult with my group and determine what I need to help with.
My tasks this week will mostly be determined by what section of the project needs the most help currently and this will be given as an update in next weeks report.
9/29/2024 Progress Report 2:
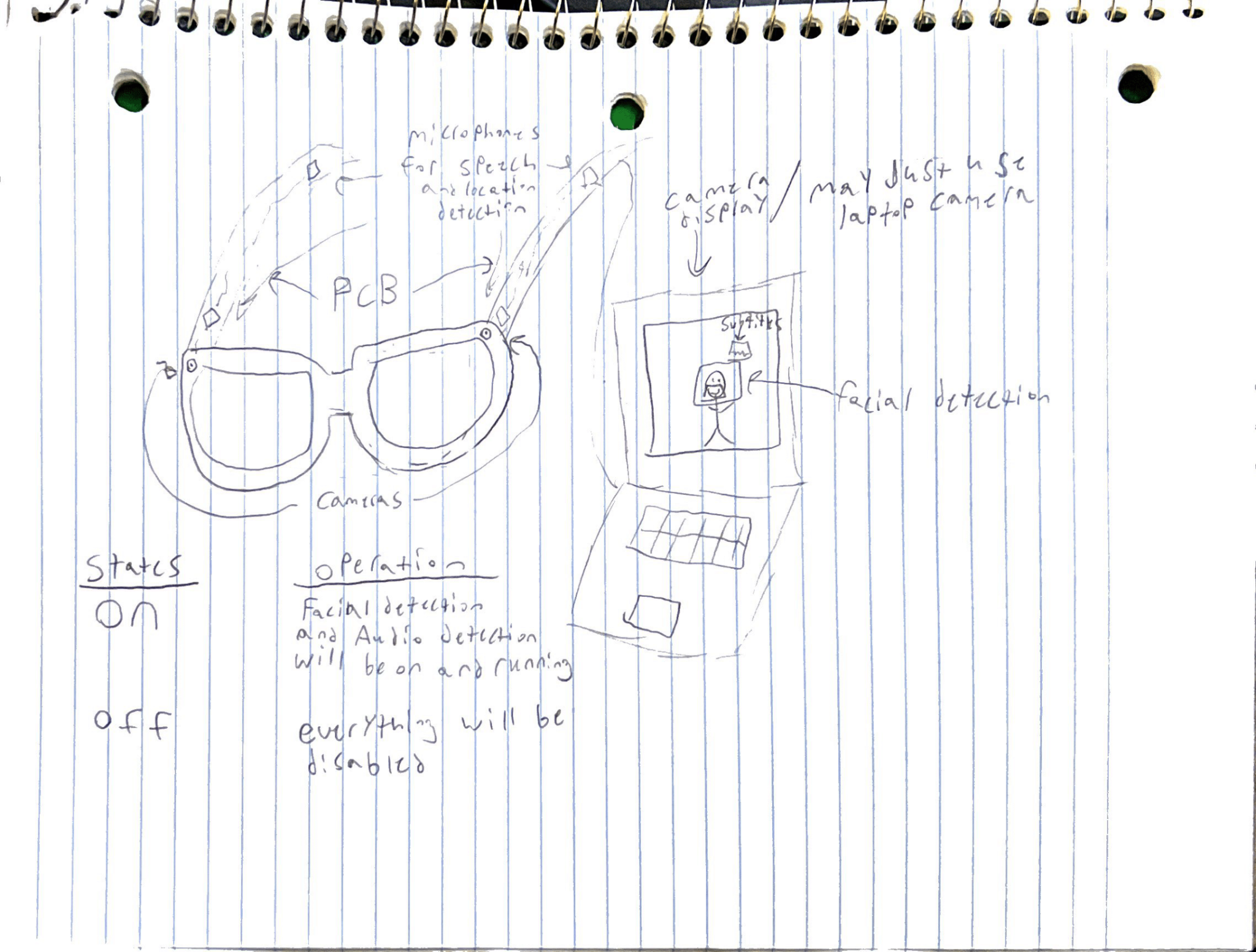
This last week did not go as planned for me. Along with my group members we determined what microcontroller and audio capturing devices we wanted to use and got them ordered. Also, we determined we would run all of our code through “FreeRTOS” onto the microcontrollers. This means that we determined we needed to switch all of our software from Python to C/C++.
My biggest mistake from this week was that I was working under the assumption that everything needed to be in C and the problem was that OpenCV libraries are mostly in C++/Python. However, I am able to work with C++ as we are able run it along with C on the “FreeRTOS” system. I spent a little too much time trying to figure out how to convert all my code to C when a simple google search could have made my workflow a lot smoother. So this will need to be added to my next weeks to do list.
To Do List Week of 9/30/24:
- Finally get to converting the facial recognition code from Python to C++ and developing the code further
- Looking into the OpenCV libraries for C++ and seeing what I have available
- Converting current facial recognition code into C++
- Adding the speech detection functionality
- If this gets complete I will assist with other operation on the IRL Subtitles project
My biggest concern for this week it the amount of time I will have with exams and events going on but now that I am sorted out on what I am able to do it should go much more smoothly this next week.
Progress Report 3:
Since CDR lots has been changed and worked on.
- From feedback during CDR we decided to run our computation through the computer and just have our esp32 boards capture audio and video and send it to the computer. This means that instead of switching to C we are keeping most of our code in Python because we have a lot more code already in Python. This also made continuing development in the facial detection department a lot easier. Shown in the picture below is the most updated picture of facial detection code that can count number of possible speech and has boxes for the placement of subtitles.
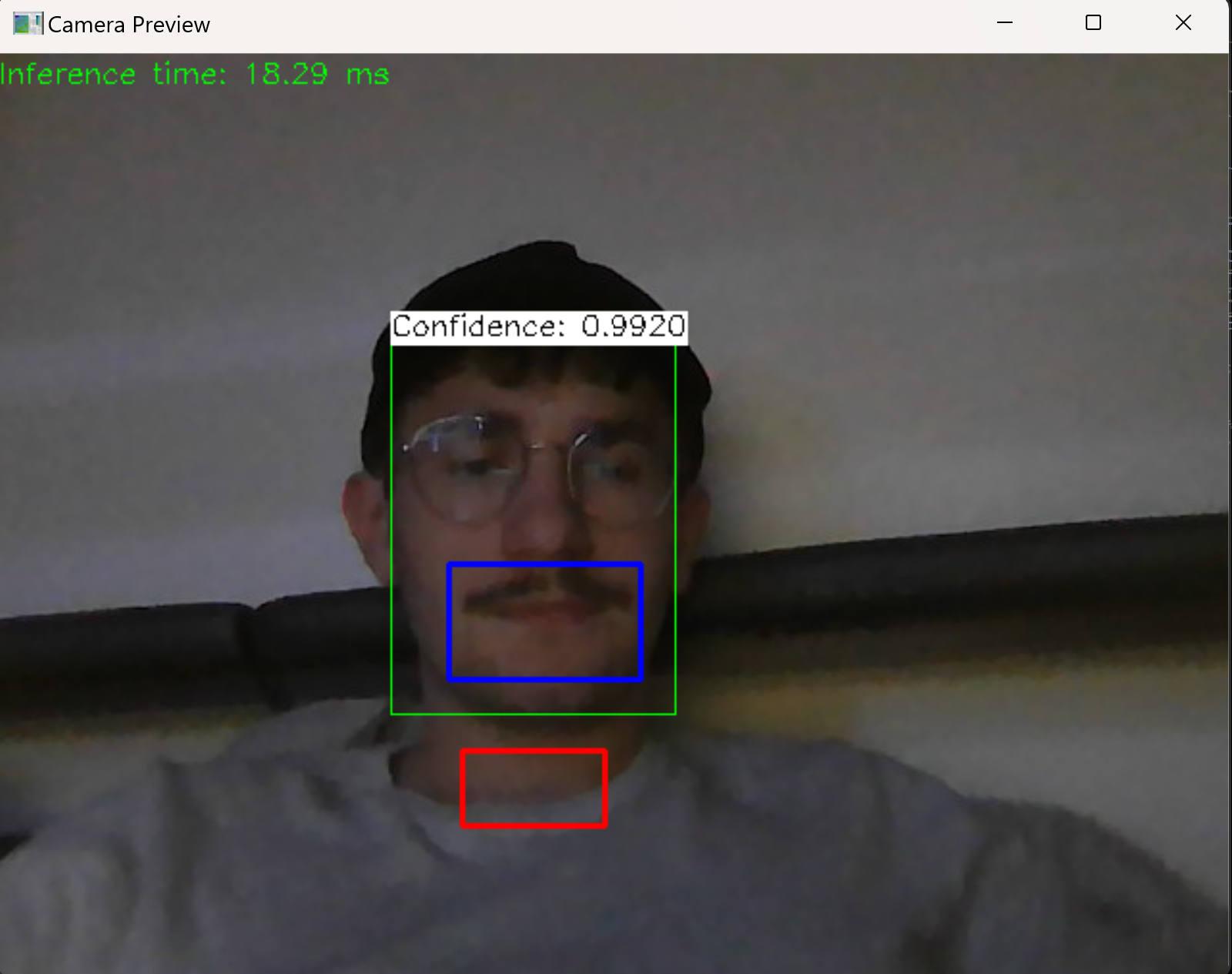
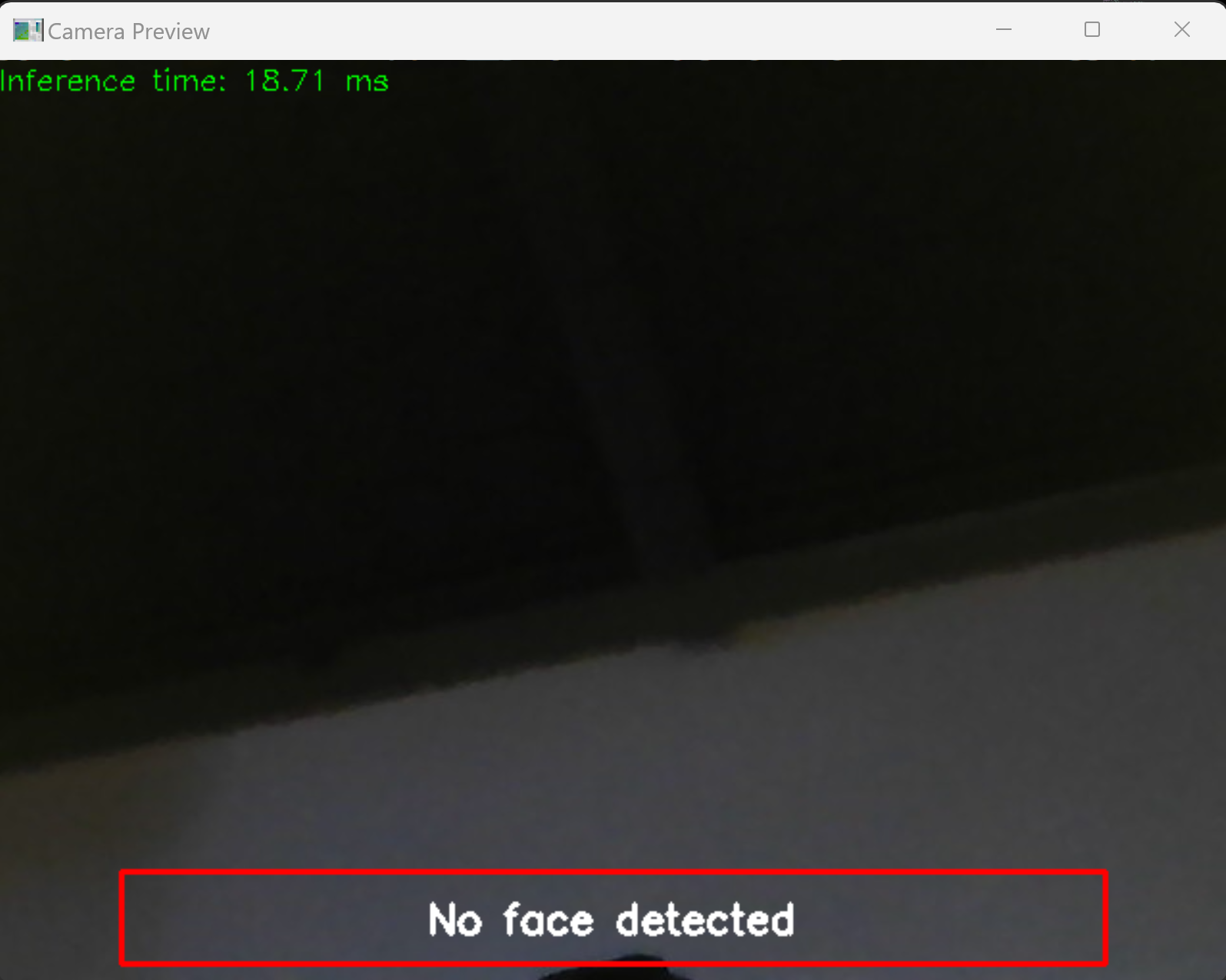
Right now the 2 states for face detection is the box at the bottom of the screen for when no faces are present and the box below the face box for when a person is present. This will be used for determining where text should be placed on the screen.
- the second part I have worked on is setting up sending data over WIFI from the esp32 s3 eye. Getting this to work was very difficult as there is not very much information on this specific board on the internet at all it was very cryptic and took a lot of time to figure out. Just recently my group mates figured out how to get the video stream sent over WIFI so we have this mostly sorted.
To Do List Week of 11/3/24:
- Develop the facial detection code to combine with other localization methods.
this will take a lot of time I am sure but if it gets done quickly I will help with other sections of the project. My main concern for this week is figuring out how to format the code with the already existing facial detection code but this should be fairly easy with Python I presume.
Final Update 12/6/24
- The facial detection code was combined with the video data sent to the web server via scraping. This was implemented by taking the video sent from the esp32-eye and using it for the Opencv code instead of the integrated camera.
- The audio and video were all sent to the same web server and we figured out how to scrape both the video and audio.
- A speech to text method was figured out and this was all combined into one environment shown up in the OpenCV display with all other methods. These were all combined the Opencv code and video scraping code were combined into one python script and the audio was called from a separate file that converted the speech to text in order to display the text inside of the boxes created from Opencv.
We have also been working on the final report and finalizing everything with our project!